Datasets 101
Peace Ossom Williamson
Sailee Pawar
Data Visualization Learning Group
presentation: http://pow123.github.io/datasets101
Continue to next slide ❱
Learning Outcomes
At the completion of this session, participants will
- be able to describe data literacy
- understand and identify areas of data responsibility in working with data
- demonstrate abilities in structuring and cleaning data
- utilize data dictionaries
- demonstrate abilities in preparing data for visualization
Data Literacy
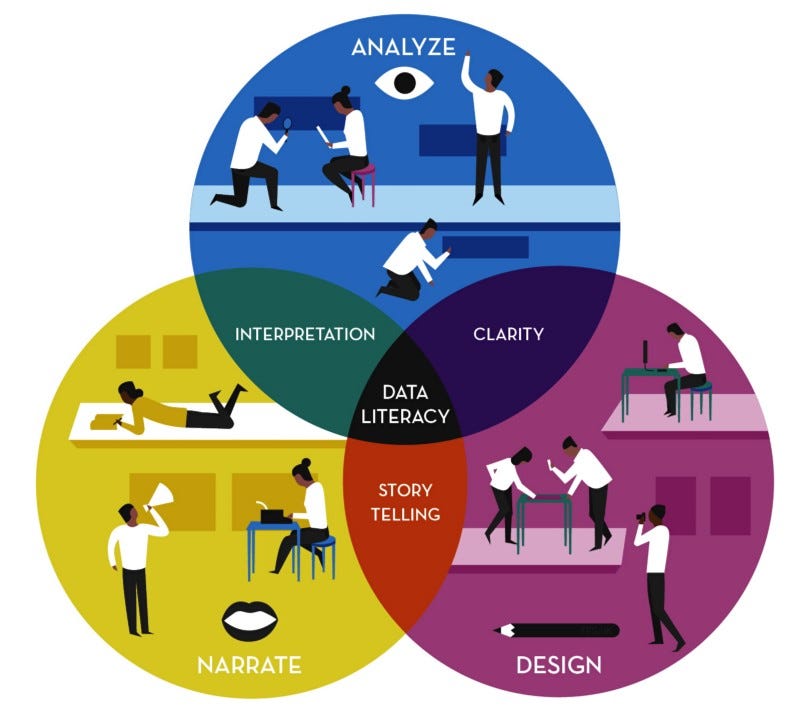
The ability to consume for knowledge, produce coherently, and think critically about data
Data Responsibility
Be aware of how data was collected. Some examples:
- Crime Statistics
- Reporting Statistics
80% voting for Trump!*
*10 people polled
... at Trump campaign office
Correlation versus Causation
When ice cream sales rise, so do homicides.
Coincidence?
Or will your next cone murder you?
Don’t confuse skepticism with cynicism.
Don’t read what you want into the data.
Before you begin
Determine what question(s) you are trying to answer.

Finding the Data
Find or request all the variables you may (or may not) need.
Taxonomy of Dirty Data
Data Structure & Formatting
- Open source file types
(For example, CSV intead of XLS)
Data Cleaning
Data Cleaning
- Field uniformity - male, MALE, man, femal, Female, F
- Field uniformity - male, MALE, man, femal, Female, F
Names are the worst -
Are Joseph Smith, JT Smith, Joe Smith, Joseph T Smith and Smith, Joseph all the same person?
- Delimitation
First and last names or address info
together or separate columns?
Data Dictionary
A file (PDF, spreadsheet, readme, etc.) that tells
- how the data is formatted (delimited text, dBase, etc.)
- the order of the variables
- the name of each variable
- the datatype of each variable (text string, integer, decimal, etc.)
- and explanation of codes (1=Male, 0=Female).
Visualization
Start with the data.
End with a story.

Tips
Last year, Americans spent X billion dollars on vitamins.
Provide context:
- Proportion
- Internal comparison
- External comparison
- Change over time
- Combination of methods
- Proportion
- Internal comparison
- External comparison
- Change over time
- Combination of methods
Tips
Other ways to provide context:
- Geographical, historical, or other breakdowns of data
- Additional data needed to ensure comparisons are fair
- Any other data to provide interesting analysis to compare or relate spending to
- Geographical, historical, or other breakdowns of data
- Additional data needed to ensure comparisons are fair
- Any other data to provide interesting analysis to compare or relate spending to


Activity
Investigate the correlation between factors (e.g., anesthesia, family size) and baby outcome (e.g., time of birth, weight, or gender). Use the data provided in the files on the LibGuide http://libguides.uta.edu/datavizlg
References
Gray, J., Bounegru, L., & Chambers, L. (Eds.). (2016). The data journalism handbook. (1st ed.) Retrieved from www.datajournalismhandbook.org/1.0/en/
Kim, W., Choi, B-J., Eui-Kyeong, H., Kim, S-K., & Lee, D. (2003). A taxonomy of dirty data. Data mining and knowledge discovery, 7(1), 81-99. doi:10.1023/A:1021564703268
McDearmon, M. (2016). Cleaning data for analysis and visualization. Retrieved from http://mikemcdearmon.com/portfolio/techposts/cleaning-data-for-analysis-and-visualization